前一章我们讨论了复制技术,即在不同节点上保存相同数据的多个副本。然而,面对一些海量数据集或非常高的查询压力,复制技术还不够,我们还需要将数据拆分成为分区(也称为分片)。
注意: 关于分区,在不同系统有不同称呼。例如 MongoDB、Elasticsearch 和 SolrCloud 中的 shard, HBase 的 region 等。
分区通常是这样定义的: 即每一条数据(或者每条记录、每行或每个文档)只属于某个特定分区。实现方式之后会逐一介绍。
采用数据分区的主要目的是提高可扩展性。不同的分区可以放在一个无共享集群的不同节点,这样一个大数据集可以分散在更多的磁盘上,查询负载也随之分布到更多的处理器上。
一些 NoSQL 数据库和基于 Hadoop 的数据仓库也都开始重视分区。这些系统有些是为事务型负载设计的,有些是分析型。但是分区技术的基本原理则普遍适用。
本章我们会介绍:
- 切分大型数据集的若干方法并讨论数据索引如何影响分区
- 分区的再平衡
- 如何将请求路由到正确的分区并执行查询
键值数据的分区
假设我们正在面临海量数据,现在需要切分它们,那么该如何决定哪些记录放在哪些节点上呢?
分区的主要目标是将数据和查询负载均匀分布在所有节点上。如果节点平均分担负载,那么忽略复制的前提下,理论上 10 个节点应该能够处理 10 倍的数据量和 10 倍于单个节点的读写吞吐量。
而如果分区不均匀,我们就称之为倾斜。倾斜会导致分区效率严重下降,在极端情况下,所有的负载可能会集中在一个分区节点上。这个节点就称为系统热点。
避免热点最简单的方法是将记录随机分配给所有节点上,但是缺点是当需要读取数据时,无法知道保存在哪个节点,导致不得不需要查询所有节点。
现在假设要存储的数据是简单的键值数据模型,即通过键来获取数据。那么我们就有以下两种方式对数据进行分区。
基于关键字区间分区
该分区方式是为每个分区分配一段连续的关键字或者关键字区间范围。如果知道关键字区间的上下限,就可以轻松确定哪个分区包含这些关键字。如果还知道哪个分区分配在哪个节点,就可以直接向该节点发出请求。
需要注意: 关键字的区间段不一定非要均匀分布,这主要是因为数据本身可能就不均匀。
分区边界可以由管理员手动确定,或者由数据库自动选择。采用这种分区策略的系统包括 Bigtable、Bigtable 的开源版本 HBase 等。
基于关键字的区间分区的缺点是某些访问模式会导致热点。
基于关键字哈希值分区
对于上述数据倾斜与热点问题,许多分布式系统采用了基于关键字哈希函数的方式来分区。一个好的哈希函数可以处理数据倾斜并使其均匀分布。
一且找到合适的关键字哈希函数,就可以为每个分区分配一个哈希范围。然而,通过关键字哈希进行分区,我们丧失了良好的区间查询特性。
在 MongoDB 中,如果启用了基于哈希的分片模式,则区间查询会发送到所有的分区上。
分区与二级索引
我们之前所讨论的分区方案都依赖于键值数据模型。键值模型相对简单,即都是通过关键字来访问记录,自然可以根据关键字来确定分区。
但是,如果涉及二级索引,情况会变得复杂。二级索引通常不能唯一标识一条记录,而是用来加速特定值的查询。
二级索引带来的主要挑战是它们不能规整的地映射到分区中。有两种主要的方法来支持对二级索引进行分区:
- 基于文档的分区
- 基于词条的分区
分区再平衡
随着时间的推移,数据库可能总会出现某些变化:
- 数据规模增加,需要更多的磁盘和内存来存储数据
- 节点可能出现故院,因此需要其他机器来接管失效的节点
所有这些变化都要求数据和请求可以从一个节点转移到另一个节点。这样一个迁移负载的过程称为再平衡。
无论对于哪种分区方案,分区再平衡至少要满足:
- 平衡之后,负载、数据存储、读写请求等应该在集群范围更均匀地分布
- 再平衡执行过程中,数据库应该可以继续正常提供读写服务
- 避免不必要的负载迁移
动态再平衡的策略
前面提到将哈希值划分为不同的区间范围,然后将每个区间分配给一个分区。也许你会问为什么不直接使用 mod,原因就是取模会导致频繁的迁移操作。
假设 hash(key) = 123456,假定最初是 10 个节点,那么这个关键字应该放在节点 6(123456 mod 10 = 6)。当节点数增加到 11 时,它需要移动到节点 3(123456 mod 11 = 3)。当继续增长到 12 个节点时,又需要移动到节点 0 (123456 mod 12 = 0)。
固定数量的分区
有一个相当简单的解决方案: 首先,创建远超实际节点数的分区数,然后为每个节点分配多个分区。接下来,如果集群中添加了一个新节点,该新节点可以从每个现有的节点上匀走几个分区,直到分区再次达到全局平衡。
唯一要调整的是分区与节点的对应关系。
原则上,也可以将集群中的不同的硬件配置因素考虑进来,即性能更强大的节点将分配更多的分区,从而分担更多的负载。
动态分区
对于采用关键字区间分区的数据库,如果边界设置有问题,最终可能会出现所有数据都挤在一个分区而其他分区基本为空,那么设定固定边界、固定数量的分区将非常不便。因此,一些数据库如 HBase 采用了动态创建分区。当分区的数据增长超过一个可配的参数阈值(HBase 上默认值是 10GB),它就拆分为两个分区。当一个大的分区发生分裂之后,可以将其中的一半转移到其他某节点以平衡负载。对于HBase,分区文件的传输需要借助 HDFS。
按节点比例分区
第三种再平衡策略是使分区数与集群节点数成正比关系。当节点数不变时,每个分区的大小与数据集大小保持正比的增长关系。当节点数增加时,分区则会调整变得更小。
自动与手动再平衡操作
全自动式再平衡会更加方便,它在正常维护之外所增加的操作很少。但是,也有可能出现结果难以预测的情况。出于这样的考虑,让管理员介入到再平衡可能是个更好的选择。
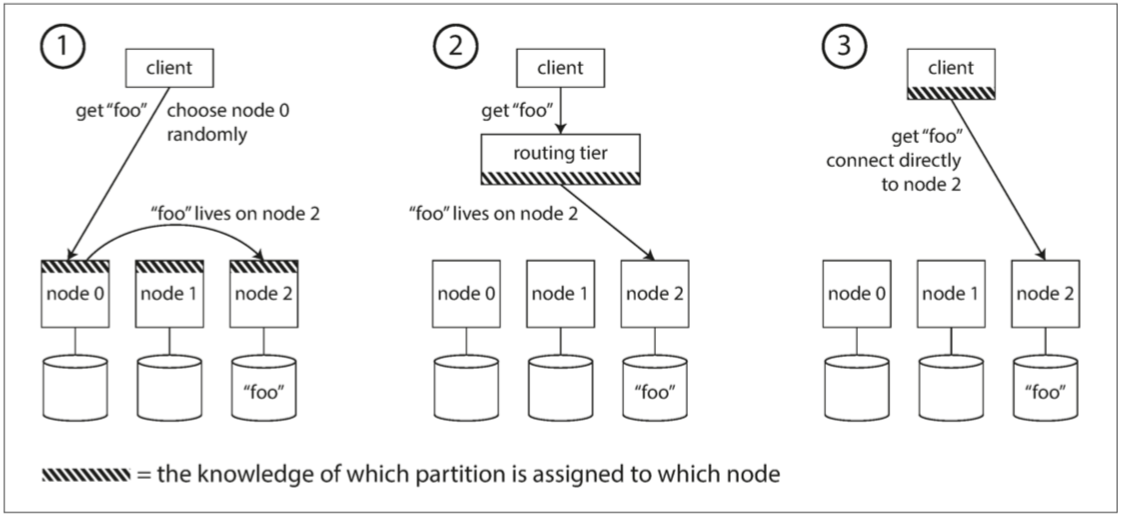
请求路由
当客户端需要发送请求时,如何知道应该连接哪个节点?这其实属于一类典型的服务发现问题,为了处理该问题,我们需要一段处理逻辑来感知这些变化,并负责处理客户端的连接。
概括来讲,这个问题有以下几种不同的处理策略:
- 允许客户端链接任意的节点,如果某节点恰好拥有所请求的分区,则直接处理该请求。否则,将请求转发到下一个合适的节点
- 将所有客户端的请求都发送到一个路由层,由后者负责将请求转发到对应的分区节点上
- 客户端感知分区和节点分配关系。此时,客户端可以直接连接到目标节点,而不需要任何中介