本章我们将讨论构建容错式分布式系统的相关算法和协议。为了构建容错系统,最好先建立一套通用的抽象机制和与之对应的技术保证,这样只需实现一次,其上的各种应用程序都可以安全地信赖底层的保证。
分布式系统最重要的抽象之一就是共识,也就是所有的节点就某一项提议达成一致。一旦解决了共识问题,就可以服务于应用层很多的目标需求。本章我们将主要研究解决共识问题的相关算法。
一致性保证
大多数多副本的数据库都至少提供了最终的一致性,这意味着如果停止更新数据库,并等待一段时间,最终所有读请求会返回相同的内容。换句话说,不一致现象是暂时的,最终会达到一致。最终一致性意味着收敛,即预期所有的副本最终会收敛到相同的值。
但是,这是一个非常弱的保证,它无法告诉我们系统何时会收敛。对于应用开发人员而言,最终一致性会带来很大的处理挑战,当面对只提供了弱保证的数据库时,需要清醒地认清系统的局限性。只有当系统出现故障或高并发压力时,最终一致性的临界条
件或者错误才会对外暴露出来。
因此本章将探索更强的一致性模型,这也意味着更多的代价。尽管会有更大的代价,更强的保证的好处是使上层应用逻辑更简单。对比了多种不同的一致性换型之后,可以结合自身需求,从中选择最合适的一种进行处理。
可线性化
在最终一致性数据库中,同时查询两个不同的副本可能会得到两个不同的答案。这会使应用层感到困惑。线性化(强一致性)的基本的想法是让一个系统看起来好像只有一个数据副本,且所有的操作都是原子的。
在一个可线性化的系统中,一旦某个客户端成功提交写请求, 所有客户端的读请求一定都能看到刚刚写入的值。换句话说,可线性化是一种就近的保证。
如何达到线性化
为使系统可线性化,我们需要添加一个重要的约束:
一旦某个读操作返回了新值,之后所有的读(包括柜同或不同的客户端)都必须返回新值。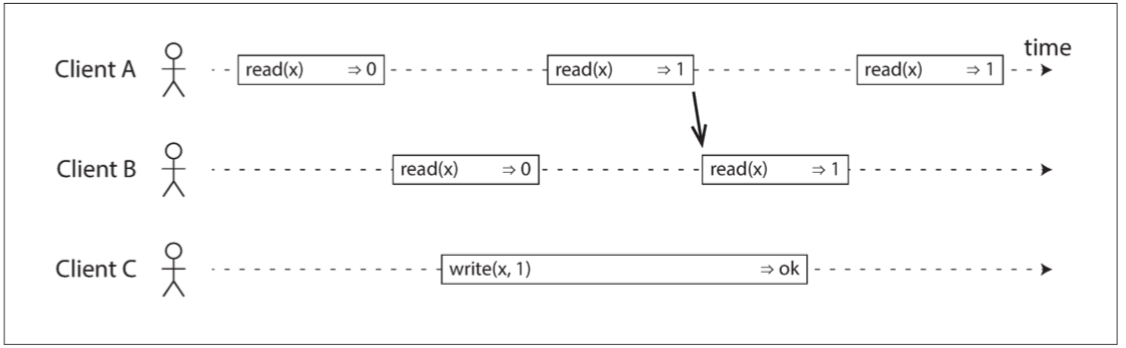
在一个可线性化的系统中,在写操作的开始与结束之间必定存在某个时间点,x 的值发生了从 0 到 1 的跳变。如果某个客户端的读取返回了新值 1,即使写操作尚未提交,那么所有后续的读取也必须全部返回新值。
线性化的依赖条件
什么情况下应该使用线性化呢?
- 加锁与主节点选举
- 约束与唯一性保证
- 跨通道的时间依赖
分布式事务与共识
有很多重要的场景都需要集群节点达成某种一致,例如:
- 主节点选举
- 原子事务提交
我们首先详细研究原子提交问题,将集中于两阶段提交(2PC)算法,这是解决原子提交最常见的方法,在各种数据库、消息系统和应用服务器中都有实现。
事实证明,2PC 是一种不算优秀的共识算法。之后,有很多更好的共识算法实现,例如,ZooKeeper 和 etcd 所使用的算法。
原子提交
原子性可以防止失败的事务破坏系统。对于在单个数据库节点上执行的事务,原子性通常由存储引擎来负责。事务提交非常依赖于数据持久写入磁盘的顺序关系: 先写入数据,然后再提交记录。
事务提交或中止的关键点在于磁盘完成日志记录的时刻:
- 如果在完成日志记录写之前如果发生了崩溃,则事务中止
- 如果在日志写入完成之后,即使发生崩溃,事务也被安全提交
注意: 事务提交不可撤销,已提交事务可以利用补偿性事务来抵消掉。
两阶段提交
两阶段提交(two-phase commit,2PC)是一种在多节点之间实现事务原子提交的算法,用来确保所有节点要么全部提交,要么全部中止。它是分布式数据库中的经典算法之一。
2PC 的基本流程如下: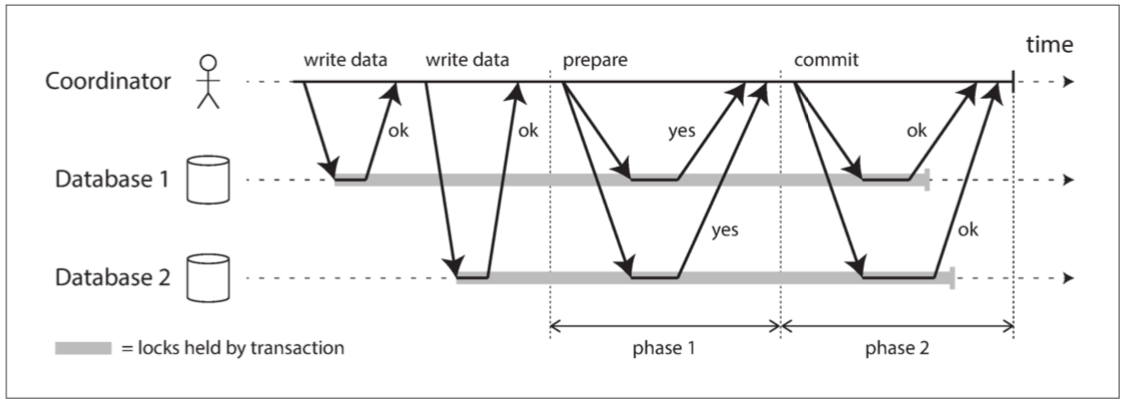
不同于单节点上的请求提交,2PC 中的提交中止过程分为两个阶段。
2PC 使用一个通常不会出现在单节点事务中的新组件: 协调者(coordinator)
当应用准备提交时,协调者开始阶段 1,它发送一个准备(prepare)请求到每个节点,询问它们是否能够提交。然后协调者会跟踪参与者的响应。如果所有参与者都回答”是”,表示它们已经准备好提交,那么协调者在阶段 2 发出提交(commit)请求,然后提交真正发生。如果任意一个参与者回复了”否”,则协调者在阶段 2 中向所有节点发送中止(abort)请求。
实践中的分布式事务
目前,许多云服务提供商由于运维方面的问题而决定不支持分布式事务。分布式事务的某些实现存在严重的性能问题。
目前有两种截然不同的分布式事务概念:
- 数据库内部的分布式事务
- 异构分布式事务
数据库内部事务由于不必考虑与其他系统的兼容,因此可以使用任何形式的内部协议并采取有针对性的优化。
XA 事务
XA 是异构环境下实施两阶段提交的一个工业标准。XA 并不是一个网络协议,而是一个与事务协调者进行通信的 C API。当然,它也支持其他语言的 API 绑定。