基本术语
数据记录的合集称为数据集(Data Set),其中每条记录称为示例(Instance)或样本(Sample),反应对象在某方面的表现或性质的事项,被称为属性(Attribute)或特征(Feature),属性张成的空间称为属性空间(Attribute Space)或样本空间(Sample Space)。例如存在一个关于西瓜的数据集,我们把色泽、根蒂、敲声作为三个坐标轴,则它们张成了一个用于描述西瓜的三维空间,每个西瓜都可以在这个空间中找到自己的坐标,因此我们也把一个示例称为特征向量(Feature Vector)。
一般地,令 D= { x1,x2,…,xm } 表示含有 m 个示例的数据集,每个示例由 d 个属性描述,d 称为样本 xi 的维数(Dimensionality)。
从数据得到模型的过程称为学习(Learning)或训练(Training)或拟合(Fitting),这个过程执行某个学习算法来完成。训练过程中使用的数据称为训练集(Training Set),其中每个样本称为训练样本(Training Sample)。
预测(Predict)是指用新的数据在模型上应用,评估(Evaluation)是指检验模型效果的手段。
若我们想要预测的是离散值,此类学习任务称为分类(Classification),若想要预测的是连续值,此类学习任务称为回归(Regression)。
对只涉及两个类别的分类任务称为二分类(Binary Classification),涉及多个类别时,则称为多分类(Multi-class Classification)。
得到模型后,使用其进行预测的过程称为测试(Testing),被预测的样本称为测试样本(Testing Sample)。
将训练集中的样本数据分为若干组,此类学习任务称为聚类(Clustering),每一组称为一个簇(Cluster)。
根据训练数据是否有标记信息,学习任务可划分为两大类:
- 监督学习
- 无监督学习
其中分类和回归是监督学习,聚类是无监督学习。
我们实际希望的是,在新样本上能表现得很好的模型,为了能够达到这个目的,应该从训练样本中尽可能学出适用于所有潜在样本的普遍规律。然而,当模型把训练样本学得太好的时候,很有可能已经把训练样本的一些特点当成所有潜在样本的一般性质,这样就会导致泛化性下降,这种现象在机器学习中称为过拟合 (Overfitting),与之相对的是欠拟合(Underfitting),是指对训练样本的一般性质尚未学好。
对于模型的泛化误差进行评估的方法有:
- 留出法: 是指直接将数据集划分为两个互斥的集合,一个作为训练集,一个作为测试集
- 交叉验证法: 是指将数据集划分为 k 个大小相似的互斥子级,每次用 k-1 个子级作为训练集,余下的那个作为测试集,这样就得到 k 组训练/测试集,从而可进行 k 次训练和测试
大多数学习算法都有参数需要设定,这称为调参(Parameter Tuning)。模型评估与选择中用于评估测试的数据集称为验证集(Validation Set)。
机器学习常涉及两类参数:
- 算法的参数: 又称为超参数,数据常在 10 以内
- 模型的参数: 数据可能很多,大型深度学习模型可能有上百亿个参数
对于模型进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,被称为性能度量(Performance Measure)。回归任务最常用的性能度量是均方误差,分类任务最常用的性能度量有错误率、精度、查准率、查全率和平衡点。
微调模型
假设现在有了一个有效的模型候选列表,需要对其进行微调,可行的方法包括:
- 网格搜索
- 随机搜索
- 集成方法
其中随机搜索是指将表现最优的模型组合起来,组合模型通常比最佳的单一模型更好。几种流程的集成方法如下:
- bagging
- boosting
- stacking
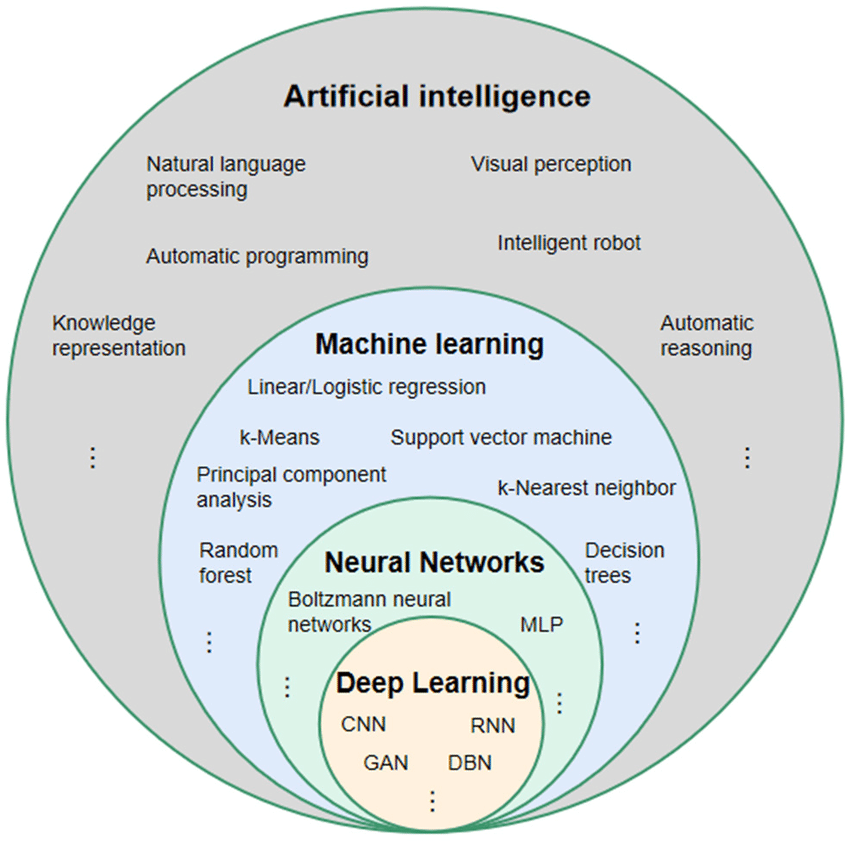
AI、Machine Learning、Neural Networks 和 Deep Learning 的关系